在日常办公中,处理大量PDF并希望将其转为可编辑Word文档是一项常见需求。本文围绕批量将PDF文件转成可编辑Word技巧展开,提供实用、易上手的步骤和注意事项,帮助工作流程更高效、更可靠。
首先,明确目标与文件类型。批量处理前应确认PDF是否为可复制文本的电子PDF,还是扫描生成的图片PDF。电子PDF可直接提取文字,图片PDF需要先进行光学字符识别(OCR)处理以得到可编辑文本。根据文件的语言、字体和排版复杂度,OCR识别准确率会有差异,必要时应预估人工校对时间。
第二,按照步骤准备文件与命名规则:
1) 将待转换的PDF文件集中放在同一文件夹中,避免子文件夹混淆;
2) 统一命名规范,如项目名_序号.pdf,有助于后续批量对应;
3) 备份原始文件以防覆盖或损坏;
4) 统计文件页数、是否包含目录或表格,以便选择合适的转换方式。
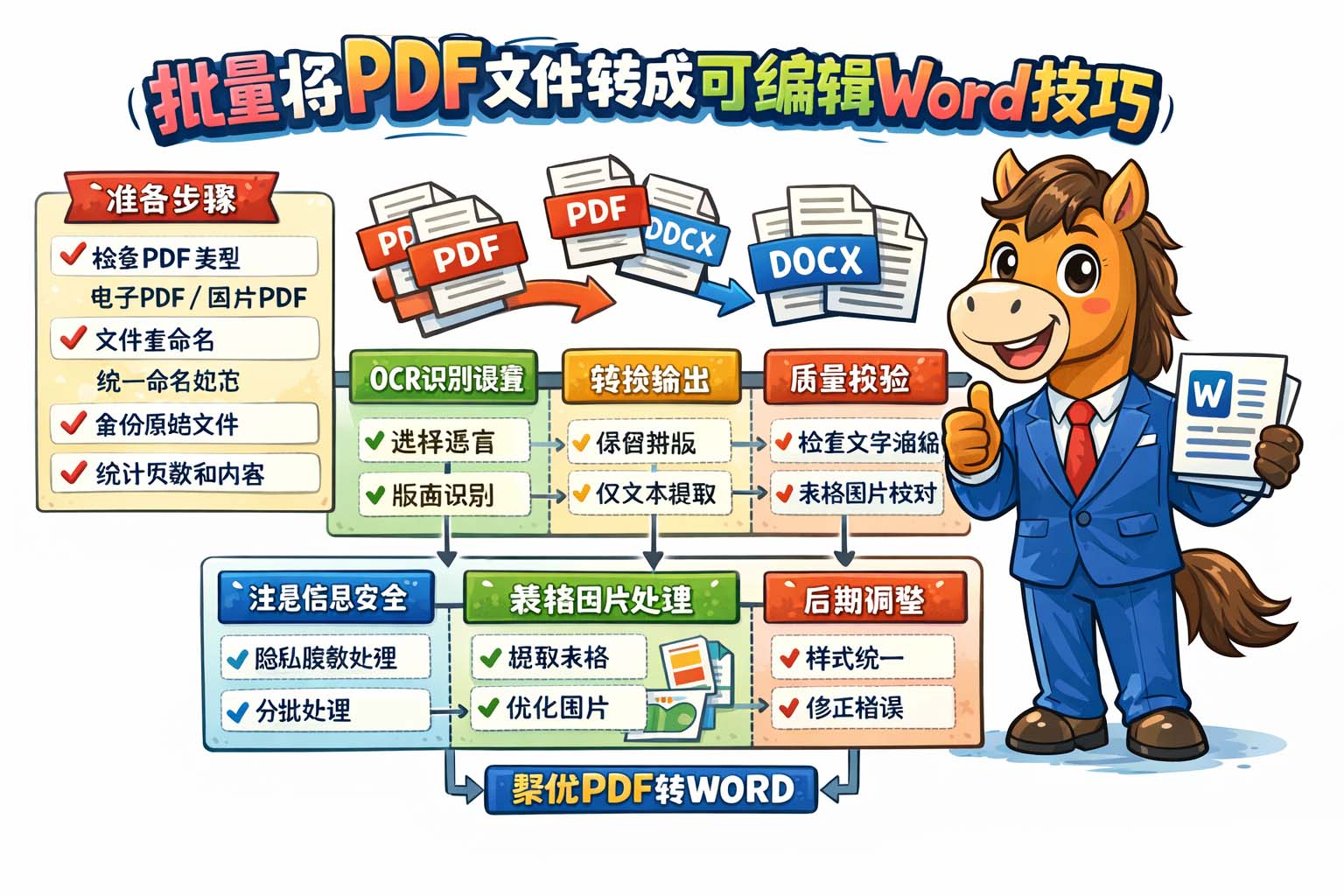
第三,选择合适的转换参数并设置输出格式。批量转换时应统一输出为可编辑的.docx格式,需考虑保留原始排版或仅提取纯文本两种目的。若希望保留复杂排版、表格和图片,应启用保留版面布局的选项;若只关心正文与可编辑性,则可选择仅保留文本以简化后续编辑。
第四,OCR设置与语言包管理。对扫描件进行OCR时,应选择与文件语言匹配的识别包,并开启版式识别和表格识别功能以提高识别质量。批量OCR时宜先对一小批文件进行试跑,检查识别错误率与段落分割情况,再调整识别精度或字符纠错字典,减少重复校正工作量。
第五,表格与图片的处理策略。若文档包含大量表格,建议提取表格为可编辑表格或先导出为CSV进行校验;图片部分若需保留,设定图片输出质量与嵌入方式,避免生成过大文件。对于多列排版或脚注,需在转换后进行手动校对并调整段落样式以保证可读性。
第六,批量流程自动化与质量抽检。建立批量转换流程时,应分阶段执行:先小范围试跑,再整批处理,最后抽样校验。抽检标准包括文字识别正确率、段落连贯性、表格完整性和图片位置。抽检过程中记录常见错误并归纳为规则,以便在下一批处理中提前过滤或预处理。
第七,后处理与样式统一。转换后应统一标题样式、段落间距与字体规格,使用查找替换功能修正规则化问题,例如断行、空格与错别字。对表格和编号目录进行二次整理,可借助批量样式替换工具快速将文档调整为统一模板,节省大量手工操作时间。
第八,注意数据隐私与敏感信息处理。批量转换前应确认是否存在敏感数据,必要时采用离线处理或先对敏感段落进行脱敏处理,避免在共享或云端处理时泄露机密。转换日志与中间文件应定期清理,备份保存在受控位置。
第九,性能与存储优化。批量转换可能占用较多CPU与磁盘空间,建议分批次处理并监控资源使用。对大文件可先拆分为单页或按章节转换,再合并为最终文档,既可防止单次任务失败影响全部文件,也有利于并行处理以提升效率。
补充实用小技巧:在遇到复杂表格或跨页表格时,可先将表格截图保存为图片,再按需手工重建表格结构或将表格拆分为多个部分分批识别;对包含数学公式、化学结构式或特殊符号的文档,优先提取文本并在转换后使用公式编辑器补回复杂内容;保留原始文件索引映射,以便在校对时快速定位并修正转换错误。长期批量需求可建立错误词库和常见替换表,提高后期批量替换效率。定期总结转换过程中的问题并更新操作手册,可在团队内部形成标准化流程,从而实现可持续的高效批量处理。保持备份与版本管理,便于随时恢复与回溯历史修改记录。实践中持续优化可节省大量时间与成本。
参考文章:批量将PDF转换成Word的技巧分享