PDF文件在办公、学习和资料整理中非常常见,但很多时候,真正需要的并不是PDF里的排版效果,而是里面的纯文字内容。比如要摘录笔记、整理文稿、复制段落、提取资料,TXT文本往往更轻便、更好编辑,也更适合后续搜索和二次处理。对于刚接触这类操作的人来说,最关心的往往不是技术难度,而是能不能一步一步看懂、照着做就能完成。下面整理出一份小白适用的PDF转TXT详细操作步骤,尽量用最直白的方式讲清楚,让普通用户也能轻松理解。
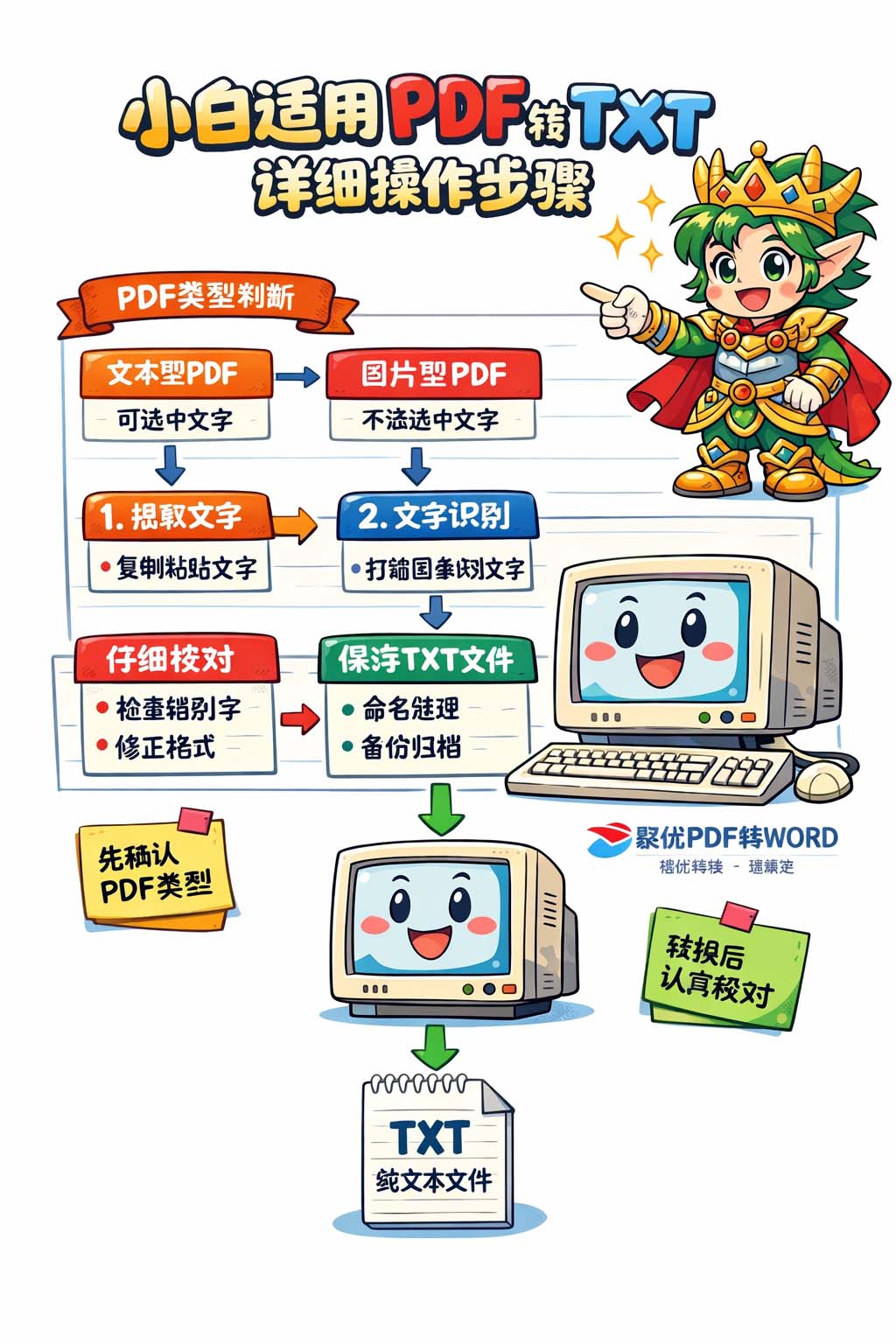
1、先确认PDF属于哪一类。PDF大致可以分成两种,一种是可以直接选中文字的文本型PDF,另一种是扫描件、图片型PDF。前者通常比较容易转换,后者因为内容本质上是图片,所以转换时可能需要先识别文字。判断方法很简单,打开PDF后用鼠标拖选文字,如果能直接选中并复制,说明大概率是文本型;如果完全选不中,或者选中的只是整页图像,那就属于图片型。先分清类型,后面的操作才不会走弯路。
2、如果是文本型PDF,最简单的思路就是把里面的文字提取出来,再保存成TXT格式。操作时重点不是追求花哨效果,而是保证内容准确。先打开PDF,逐页查看文字是否完整,尤其注意页眉、页脚、表格、脚注这些容易被忽略的地方。随后再把需要的文字复制出来,整理到一个纯文本文件中。纯文本最大的好处是干净,不带复杂格式,保存后打开速度快,后续修改也方便。对于只想拿到文字内容的人来说,这一步通常最直接,也最省事。
3、如果PDF内容比较长,建议按章节或页面分段处理,不要一次性全部复制后再慢慢清理。这样做的好处是更不容易漏字,也能更快发现格式问题。比如复制一页后,先检查段落是否断开、空行是否过多、换行是否混乱,再继续下一页。很多初学者在转换时会遇到文字粘连、段落错位、标题混进正文的问题,分段检查就能明显减少返工。对新手来说,细一点反而更快,因为后面不用大范围修改。
4、如果是扫描件或图片型PDF,就要先把图像里的文字识别出来,再整理成TXT。识别完成后,最容易出现的问题是错别字、数字识别错误、标点丢失、空格混乱,所以不能把识别结果直接当成最终文件。正确做法是先把识别后的文字通读一遍,重点检查专有名词、数字、日期、英文、单位符号和容易混淆的字。比如“0”和“O”、“1”和“I”、“8”和“B”这类字符,经常在识别时出错,整理时要特别留意。只要多花一点时间校对,最终的TXT就会更可靠。
5、转换完成后,建议马上做一次最基础的整理。先把明显多余的空行删除,再把被切断的句子连接起来,把标题、正文、列表分开。TXT文件虽然简单,但越简单越要整洁,否则后面查找内容时会很费劲。整理时可以按照“标题一行、正文一段、列表分点”的方式排列,这样既便于阅读,也便于复制到其他文档中继续编辑。对于经常处理资料的人来说,TXT不是最终展示格式,而是一个便于提取和整理的中间格式,所以越清楚越有价值。
6、保存文件时,最好使用容易识别的文件名,例如“合同文字版TXT”“会议纪要纯文本”“资料提取文本”等,这样以后查找更快。文件夹也建议按日期、主题或项目分类保存,避免大量TXT文件混在一起。很多人以为转换完成就结束了,其实后续归档同样重要,因为资料一多,找不到原文件会比转换本身更麻烦。把命名和分类做好,后面再处理同类PDF时效率会高很多。
7、想让小白适用的PDF转TXT详细操作步骤更顺手,关键还在于养成两个习惯:一是先看清文件类型再动手,二是转换后一定要校对一遍。前者决定效率,后者决定质量。只要按照“先判断、再提取、后整理、最后保存”的顺序来做,即使没有经验,也能比较稳妥地完成转换。对于日常办公、学习摘录、资料汇总、内容备份来说,TXT格式都非常实用,文件轻、打开快、编辑方便,特别适合快速整理文字内容。
总的来说,PDF转TXT并不复杂,真正重要的是方法清楚、步骤稳定、细节认真。只要把文件类型分清,把文字提取后再校对整理,普通用户也能轻松完成一份干净、可用、方便后续编辑的TXT文本。对于需要经常处理资料的人来说,这类操作看似简单,但只要做得规范,就能明显提升资料整理效率,也能让后续搜索、复制、归档都更省心。
上一篇: 如何在电脑上完成PDF转Word操作?