在日常办公或学习中,经常需要把PDF里的文字提取为纯文本格式,以便后续检索、编辑或备份。下面介绍一套不借助第三方软件完成PDF到TXT的方法,步骤清晰、易于操作,适用于常见的操作系统和办公场景。全文按步骤分点说明,便于按步执行。
第一步:使用系统自带的打印或导出功能。许多操作系统和PDF阅读器自带“另存为”或“导出”为文本的选项。打开需要转换的PDF文件,选择“另存为”或“导出”为TXT或文本格式,如果界面没有直接选项,可选择打印为文本或利用打印对话框中的“另存为”功能保存为纯文本文件。
第二步:借助操作系统的复制粘贴功能。若PDF文档为可选文本格式,可以直接全选或分段选择文字,复制后粘贴到记事本或任何文本编辑器,最后另存为TXT文件。此方法适合页面不多、格式不复杂的文档,但需要注意分页符、换行和特殊字符的清理。
第三步:利用系统自带的OCR功能进行图像型PDF的识别。若PDF是扫描件或图像形式,现代操作系统常内置OCR或可通过打印对话框中的“保存为PDF/A”后采取系统识别方式转换为可选文本。也可在预览或阅读器中开启文字识别并复制识别结果,随后保存为TXT文件。识别后需要检查识别错误并作必要校对。
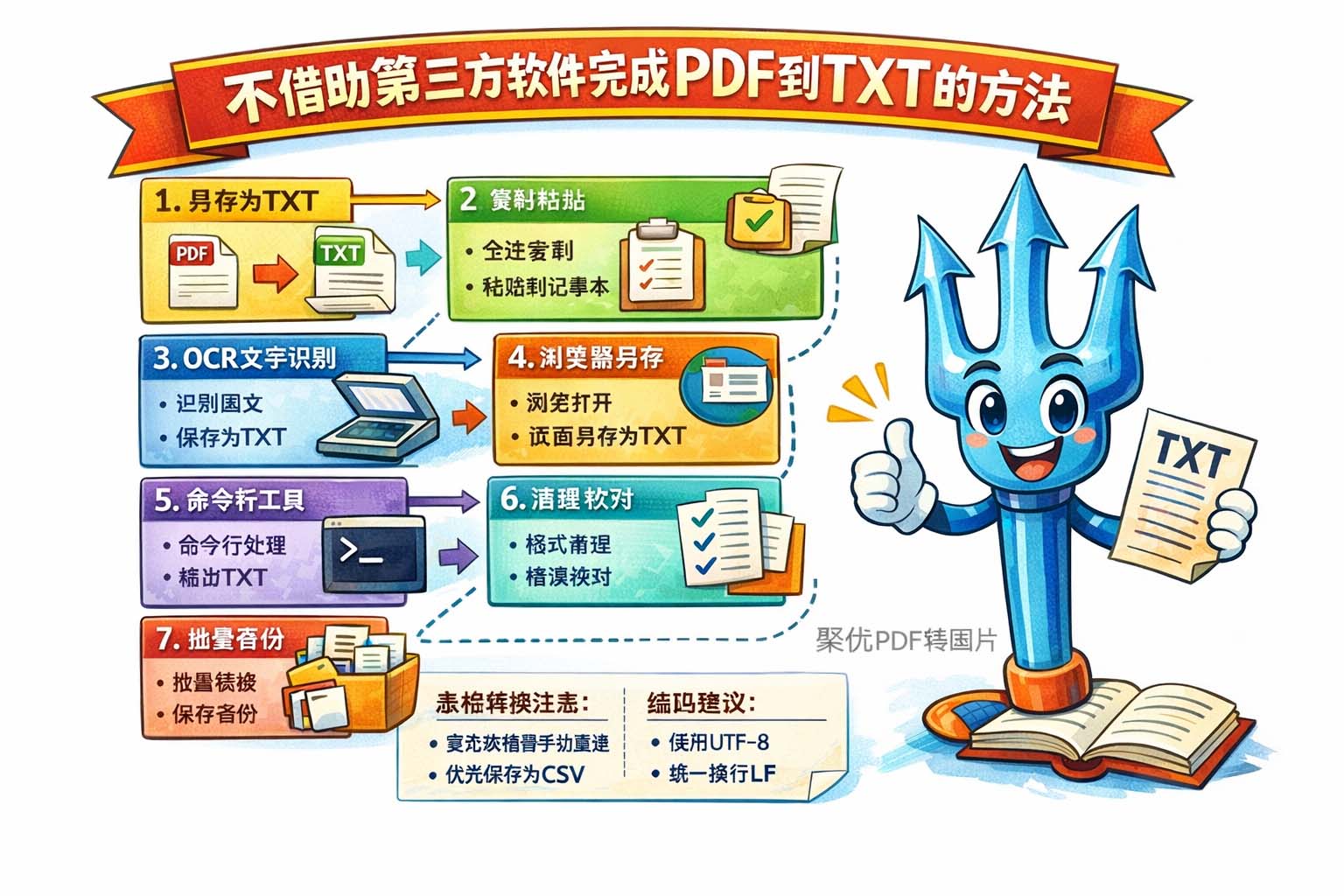
第四步:通过网页浏览器打开并保存为文本。多数浏览器能够直接打开PDF文件。将PDF拖拽到浏览器窗口后,使用“另存为”或“保存页面为纯文本”的功能,或者全选复制页面内容并粘贴到文本编辑器,最后保存为TXT。这一方法无需安装额外工具,适合小白用户。
第五步:使用命令行的系统工具(适用于熟悉命令行的用户)。在类Unix系统中,系统自带的一些文本处理命令可以配合使用,以提取PDF中的文本(例如通过打印到文本输出或使用系统可用的转换接口)。在Windows中,可以利用PowerShell内置的处理手段将可选文本导出并保存为TXT文件。此类方法对批量处理或自动化有帮助,但应注意命令的参数与编码配置。
第六步:清理与校对。无论采用哪种不借助第三方软件完成PDF到TXT的方法,保存后的TXT文件通常需要清理格式,如去除多余换行、修复断行、替换不规范空格和检查错别字。使用文本编辑器的查找替换功能或正则替换可以提高效率。最后将文本以UTF-8或所需编码保存,以确保跨平台显示正确。
第七步:批量处理技巧与备份建议。对于多文件转换,可依靠系统自带的脚本或批处理能力,循环打开并执行导出或复制操作,减少重复劳动。完成转换后建议保留原始PDF一份作为备份,便于日后对照或恢复。
另外,表格和复杂排版的PDF在转换为TXT时信息会丢失,需手动重建表格结构或保留为CSV格式以便后续处理。注意字符编码选择和换行规范,优先使用UTF-8并统一换行符为LF,以降低在不同系统间的兼容性问题。若对原始格式有严格要求,可在转换前列出需要保留的要素并逐项处理,从而保证TXT文件在可读性与后续利用上达到最佳效果。
参考文章:不装软件也能完成PDF转TXT的技巧
上一篇: 不装软件实现PDF文字导出到TXT小技巧