不装软件也能完成PDF提取文字的技巧在办公与学习中非常实用。面对手头只有PDF但需要文字内容的情况,可以用若干无需下载安装的做法快速得到高质量文本,下面以分步方式说明,便于普通使用者轻松上手并保证结果可编辑、可搜索、便于后续处理。
1. 直接复制法。若PDF内部是真文本而非扫描图片,可在浏览器或自带阅读器中打开,用鼠标选中需要的段落,复制并粘贴到记事本或文档中。复制后检查换行与空格,必要时统一段落断行。
2. 浏览器另存与导出法。部分内置查看器支持“另存为”或导出为HTML、TXT等格式,利用该功能可把文字提取为可编辑文件,再进行格式清理和编码转换,避免乱码。
3. 在线OCR法。若PDF由扫描图片构成,可使用可信赖的在线文字识别服务上传PDF,并选择正确语言和输出格式,等待处理后下载或复制识别结果。识别前可先裁剪页面或分割大文件,以提高准确率。
4. 手机拍照识别法。利用手机自带的扫描或相机识别功能对纸质或屏幕上的PDF页面拍照,开启文字识别导出为文本;对长文档可分批拍摄并合并结果,再做版式与段落修复。
5. 屏幕截图+识别法。当页面被保护或无法直接复制时,可对关键区域截图,然后使用网页或手机端的图片识别功能提取文字,适合处理含表格或特殊字体的局部内容。
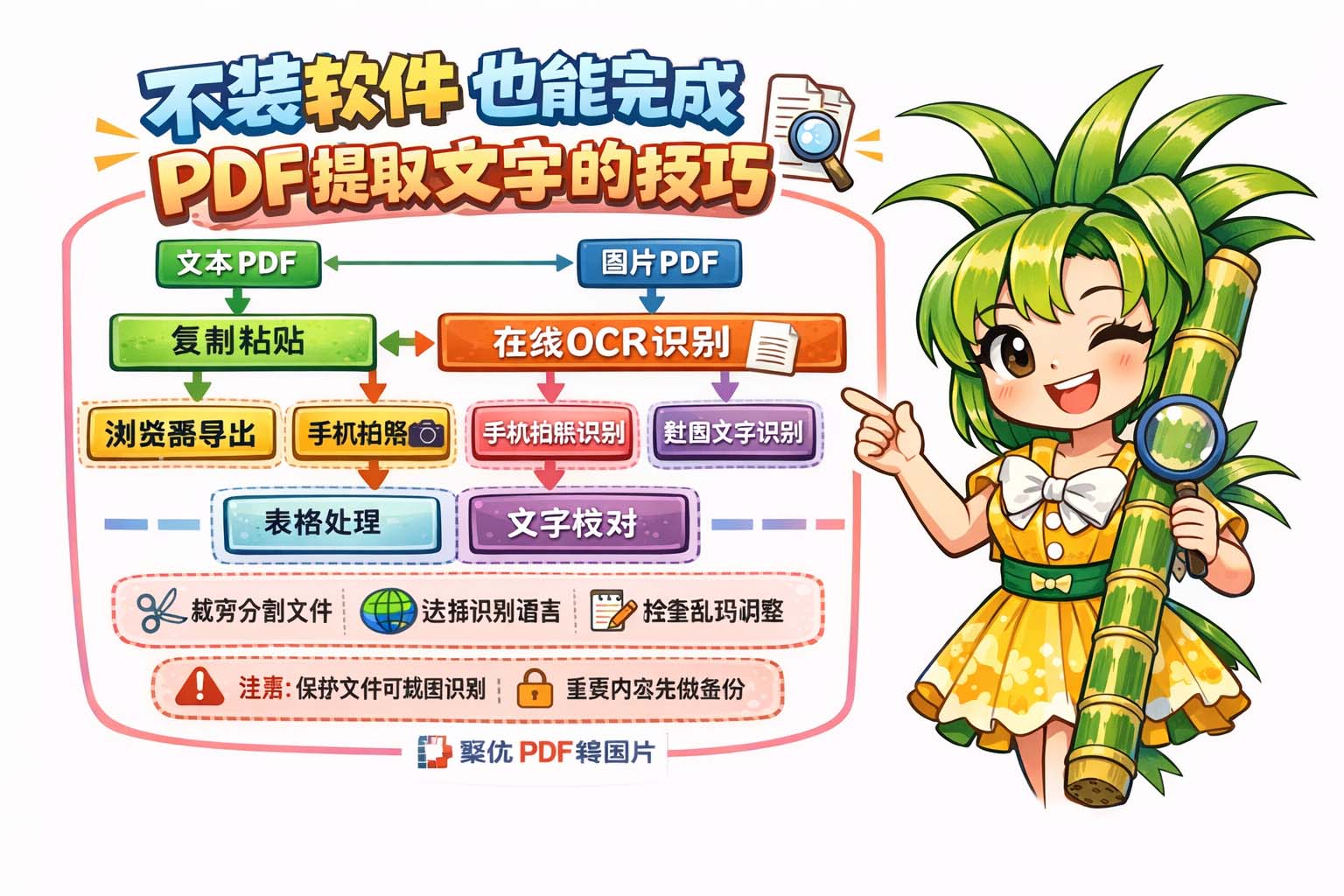
6. 表格与复杂排版处理法。表格可先单独截图为图片,再用支持表格识别的在线服务导出为CSV或表格文本,导入表格处理软件进行校验;公式与特殊符号可手动修正或用专业识别模块逐页核对。
7. 文本清理与校对。提取后建议按步骤清理:统一编码为UTF-8、替换多余换行、修正连字符问题、校对专有名词与数字。对重要文档可比对原文逐段校验,以确保关键数据无误。
8. 精准提取的小技巧。先判断PDF类型(文本层或图片层),再选对应方法;处理批量文件时先分批小样本测试识别参数;识别语言与方向设置要正确;处理机密信息时选用支持加密传输的在线服务或直接在本地设备完成拍照识别以减少风险。
9. 常见问题及应对。遇到乱码先尝试更换编码或另存为不同格式;遇到识别错误可通过提高分辨率或裁剪去除干扰边框;遇到页面保护限制可尝试截图识别或请求原始文档。
以上方法在不装软件也能完成PDF提取文字的技巧这一主题下,提供从简单复制到复杂OCR的全流程方案,既能满足日常快速提取的需求,也能应对扫描型或排版复杂的文档。按步骤操作并进行必要校对,大多数情况下可以在不额外安装程序的前提下获得准确、可编辑的文字结果,为后续编辑、索引或翻译工作节省大量时间和精力。 在处理大量文件时建议先建立目录与命名规则,记录处理参数与识别语言,便于复现和批量后处理。对于含有敏感信息的PDF,应优先选用本地拍照识别或确认在线服务具备加密传输和隐私承诺。反复使用本方法可熟练掌握不装软件也能完成PDF提取文字的技巧,从而在不依赖额外安装的条件下提高办公效率和文字资源的可用性。
最后,务必在重要场景中保留原始PDF的备份,并记录识别后文本的版本变化,便于溯源和审计。 采用这些步骤,日常提取将更加稳定可靠。 实践几次后会更熟练。
参考文章:不装软件也能完成PDF转TXT的技巧